 Character Usage
Character Usage
Updated as of 8 February 2021.
Introduction
“What does the Character Usage Report do?”
This report is like the WordWheel in the Search Window, but it shows an overview of individual characters used within the text. This report is beneficial for those editing a text to:
- Identify unwanted characters.
- Identify mismatched punctuation pairs.
- Learn more about characters throughout different types of text.
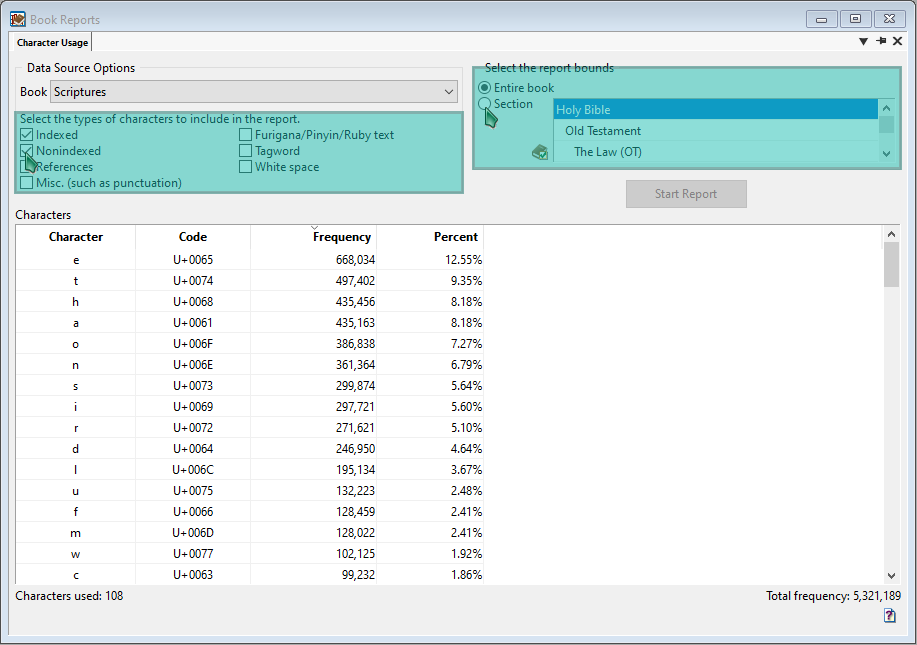
The Character Usage Report displays the frequency of all the characters used in the text. It also shows the Unicode values, frequency, and percentage of those characters.
To access this report, go to Analyze > Book Reports > Character Usage Report.
To start the report:
- Select the types of characters to include in the report.
- Select whether you want to analyze the entire book or a section of the book in the upper-right menu.
- Click on the Start Report button.
This will show a table of every character used within the text. By double-clicking on a character, it will open a Search Results window with every instance of the character used within the text.
Unwanted Characters
“What is an unwanted character and how do I find it?”
There are a couple definitions for an unwanted character.
- A character that is used throughout a text that looks normal, but it is used incorrectly. For example, you might want to look at all hyphens to identify where an em dash or en dash are more appropriate.
- A character that is used but is the wrong character altogether. For example, it is likely to see hyphens, em dashes, and en dashes in a text, but there are other related dash characters such as the two-em dash (⸺), three-em dash (⸻), figure dash (‒), horizontal bar (―), Hebrew Maqaf (־), and so forth.
To identify unwanted characters:
- Start the report with only
Misc. (such as punctuation)checked in the types of characters to include in the report. - Look through the table of characters for similar-looking characters or characters that are often used incorrectly. For example, you may want to look at all double quotes and make sure they are all smart quotes (e.g., “ versus “).
- Double-click on the character(s). This opens a Search Results window, and you can scan though the results to find incorrect or unwanted characters.
- If possible, correct them in the text you are working on (e.g., a Word document that you’ve added to WordCruncher).
Mismatched Pairs
“What is a mismatched punctuation pair and how do I find it?”
Paired punctuation is a type of punctuation that requires an open and a close form, such as parentheses, quotations, and brackets. If there are more open parentheses than close parentheses, you likely have mismatched punctuation. There are exceptions to this rule, like when a quote extends for several paragraphs, but these are good things to check.
To identify mismatched pairs:
- Start the report with only
Misc. (such as punctuation)checked in the types of characters to include in the report. - Double-click on the open-paired punctuation, such as (, [, or “.
- Pin the search results tab. There is a pin icon in the upper-right corner of the results window. By pinning it, you should see a pin next to the “List 1” in the upper-left corner.
- Go back to the Character Usage Report. Double-click on the close-paired punctuation, such as ), ], or ”.
- Pin the search results tab like in Step 2. You should see a pin next to “List 2”, as well.
- Go to
Window > Split Vertically. This splits your search results window in half. - On the left window, select List 1 from the upper-left tabs. On the right window, select List 2 from the upper-right tabs.
- Go to
Results > Delete > Delete Matching Synchronous References. This will remove any search results that already have matching punctuation.
Character Types
“What are all the different types of characters that I can include in the report?”
Indexedtext consists of the majority of the characters within your text, including all words of your text. If punctuation is embedded in the word, then punctuation also shows up here.Nonindexedtext consists of the characters that have been specifically marked as nonindexed, meaning that it does not show up in the WordWheel at all. WordCruncher books occasionally use this for headings and the table of contents, since this text is unlikely to be key to search queries. This option is very rarely used by most users.Referencesrefer to the text used within the table of contents. For example, the book might have a table of contents. Any text within the table of contents isn’t actually in the text, but it’s considered a reference level. This option is very rarely used by most users.Misc. (such as punctuation)will show subwords, which includes punctuation but excludes words. This option is useful for identifying unwanted punctuation or mismatched punctuation.Furigana/Pinyin/Ruby textis the text in some books that is commonly used in Japanese or Chinese. Generally, this text is above the actual text for pronunciation help.Tagwordtext is used in a few WordCruncher books, which are hidden, embedded text that indicates a word’s topic, morphological information, etc. This option is very rarely used by most users.White spaceare any type of tabs or spaces used throughout the text. This can be useful to find non-breaking spaces.